零拷贝(Zero-Copy)是一种可以在计算机系统中,通过减少 CPU 拷贝数据次数、绕开内核进行直接 IO 等方式,提高系统 IO 性能的一种技术。
通过 DMA 减少 CPU 拷贝次数 减少拷贝次数的原理主要是通过减少数据拷贝的次数,减少CPU的使用,提高数据传输的效率。在传统的数据传输过程中,数据通常需要在用户空间和内核空间之间进行至少两次的拷贝,这就会消耗大量的CPU资源。而零拷贝技术则是通过一些特殊的技术手段,尽可能地减少数据的拷贝次数,从而提高数据传输的效率。
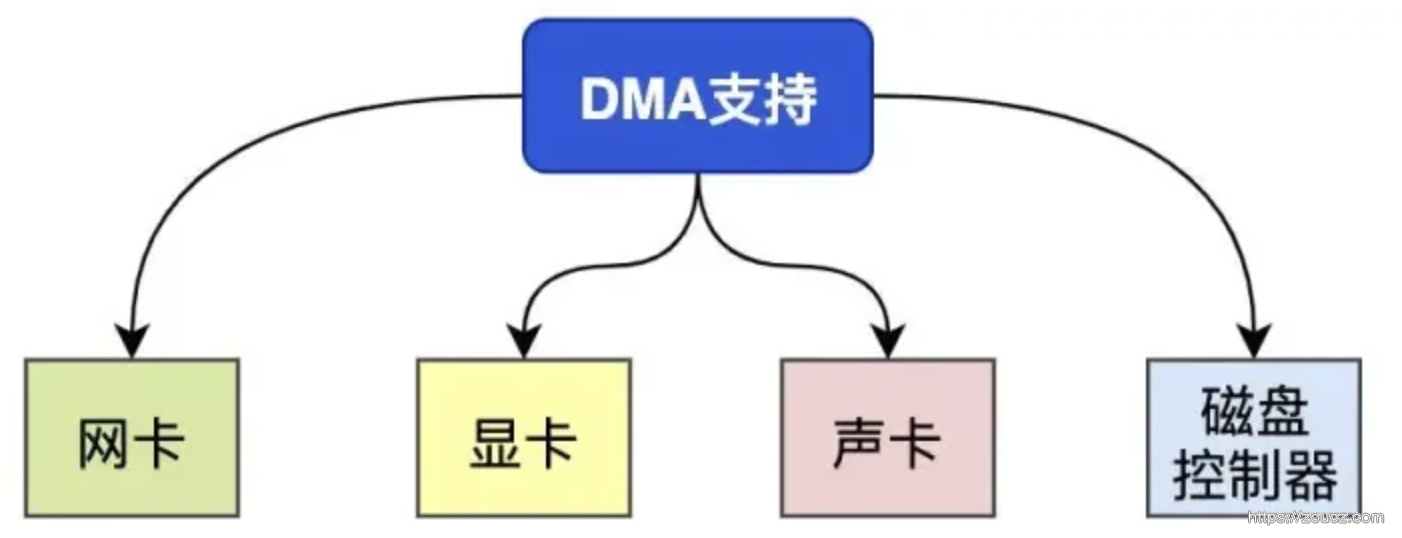
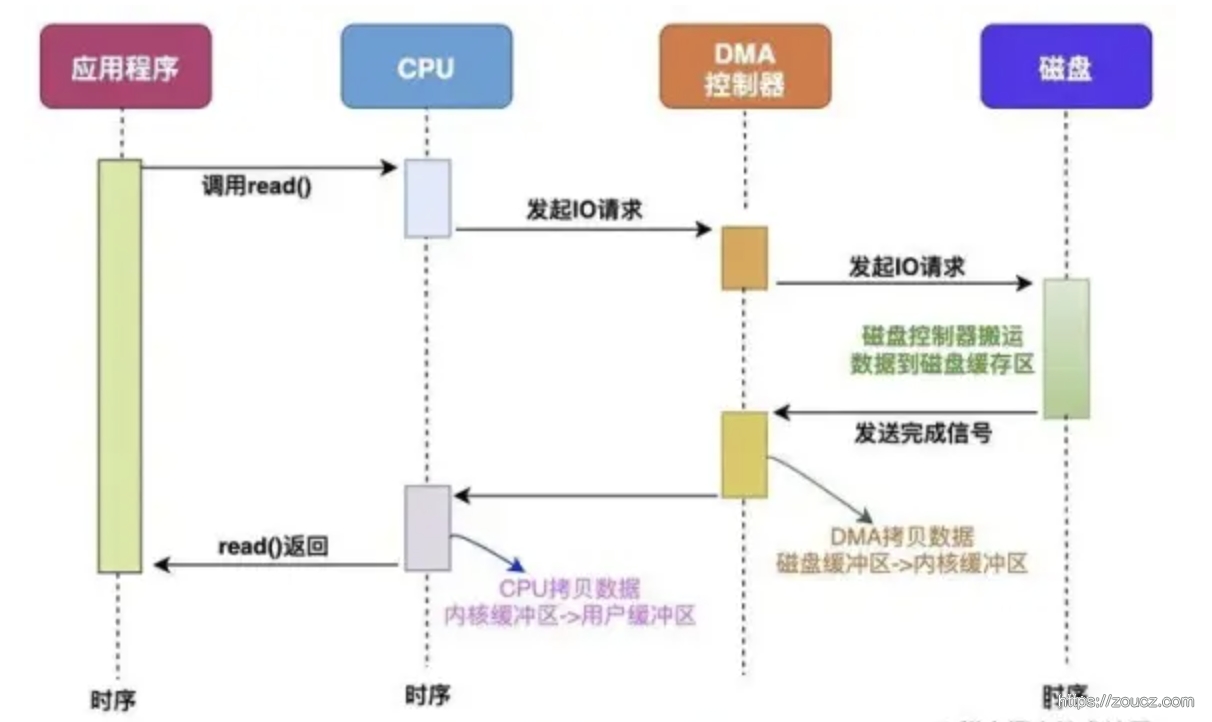
DMA(Direct Memory Access) 直接内存访问是一种可以让某些硬件子系统(例如高速磁盘驱动器、图形卡)在不涉及CPU的情况下,直接访问内存的技术,从而实现零拷贝。
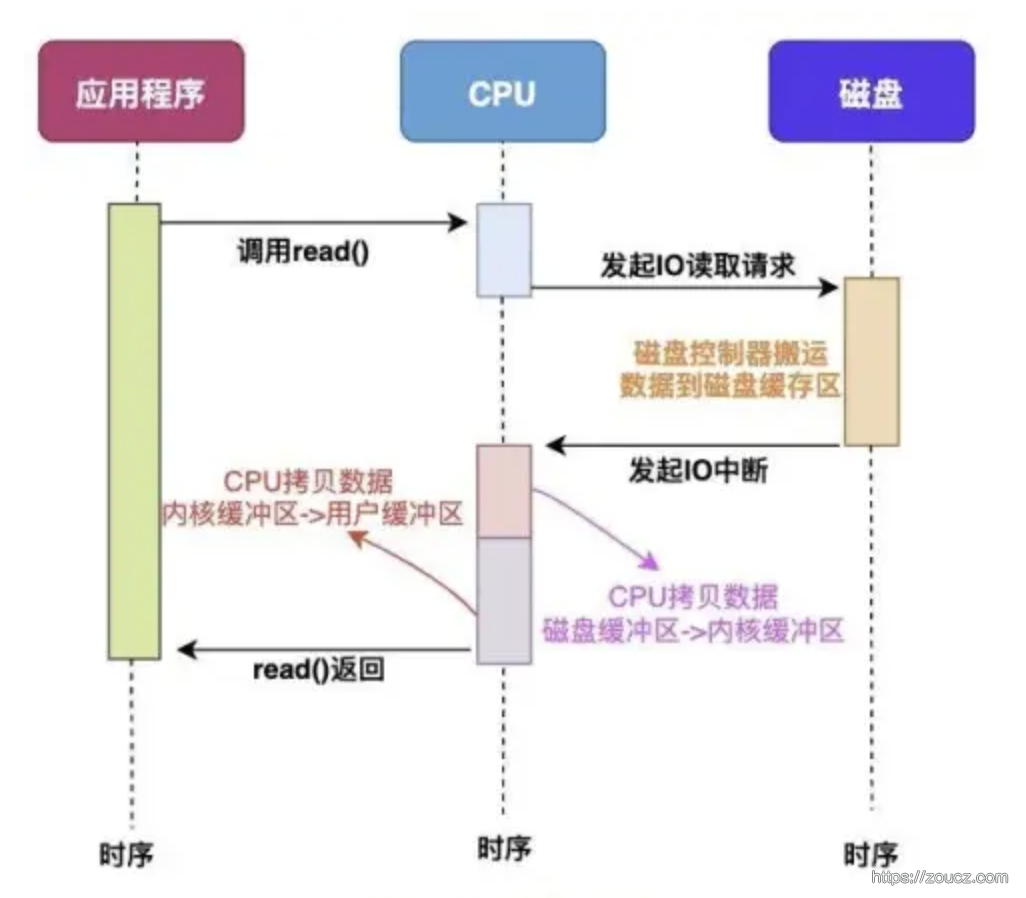
直接使用 CPU 的 IO 普通的 IO 方式,CPU 参与了全部 IO 的工作,并存在数据从内核态到用户态拷贝的过程。
CPU + DMA 的 IO 目前支持 DMA 的硬件包括:网卡、声卡、显卡、磁盘控制器等。
加上 DMA 设备后,CPU 参与的环节有所减少,但是整个 IO 过程扔存在内核态到用户态的拷贝过程
操作系统提供了一些方法,能进一步减少 CPU 参与的 IO 环节,让数据不再从内核缓冲区的内存页拷贝到用户缓冲区,减少数据拷贝的次数。
mmap 概念和适用场景
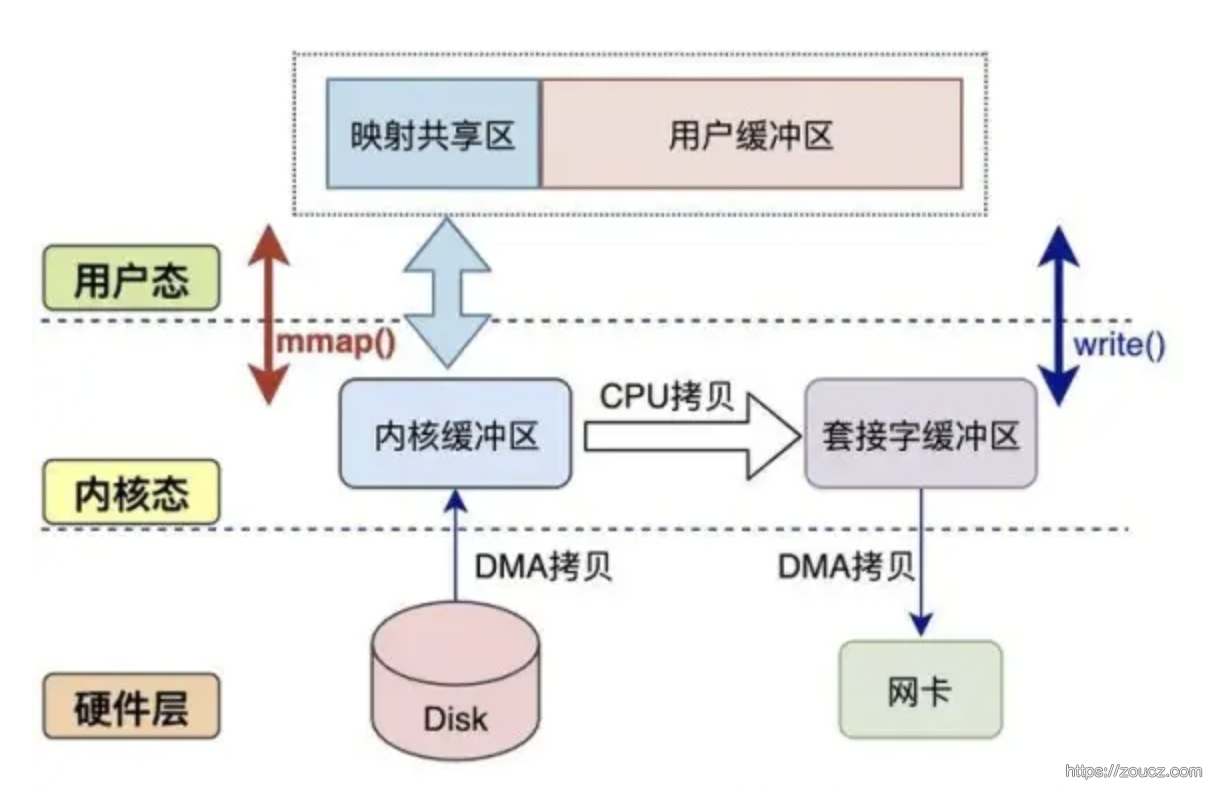
该函数可以将一个文件或者其它对象映射进内存,通过对这块内存的读写操作,程序可以实现对文件或者其它对象的读写操作。这样就避免了数据在用户空间和内核空间之间的拷贝,从而减少了一次从内核态到用户态的拷贝过程。
mmap适用的场景:
文件I/O性能要求较高的场景:mmap将文件映射到内存,可以避免数据在用户空间和内核空间之间的拷贝,从而提高文件I/O性能。
大文件处理:对于大文件,使用mmap可以避免一次性将整个文件读入内存,减少内存占用,提高处理效率。
多个进程共享内存的场景:mmap可以用于实现进程间通信(IPC),通过将一个文件映射到多个进程的内存空间,实现进程间数据共享。
内存数据库:mmap可以用于实现内存数据库,将数据库文件映射到内存,提高数据访问速度。
Redis、Nginx、Lucene、LevelDB、SQLite 等应用中在一些场景下使用了 mmap 来优化 IO 效率。
示例代码 下面是两段示例代码,来对比使用 mmap 和普通 IO 的性能差异。
构造测试数据,向磁盘中写入一个文件 test_data.txt,1GB 大小,每行 100~200 个字节的文本字符。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 #include <fcntl.h> #include <stdio.h> #include <stdlib.h> #include <time.h> #include <unistd.h> #define FILE_SIZE (1024 * 1024 * 1024 ) #define MIN_LINE_SIZE 100 #define MAX_LINE_SIZE 200 char random_char () int r = rand() % 62 ; if (r < 10 ) { return '0' + r; } else if (r < 36 ) { return 'A' + r - 10 ; } else { return 'a' + r - 36 ; } } int main () int fd; size_t written_bytes = 0 ; srand(time(NULL )); fd = open("test_data.txt" , O_CREAT | O_WRONLY | O_TRUNC, 0644 ); if (fd < 0 ) { perror("open error" ); exit (EXIT_FAILURE); } while (written_bytes < FILE_SIZE) { int line_size = MIN_LINE_SIZE + rand() % (MAX_LINE_SIZE - MIN_LINE_SIZE + 1 ); char buffer[MAX_LINE_SIZE + 1 ]; for (int i = 0 ; i < line_size; ++i) { buffer[i] = random_char(); } buffer[line_size] = '\n' ; ssize_t to_write = line_size + 1 ; ssize_t remaining = FILE_SIZE - written_bytes; if (to_write > remaining) { to_write = remaining; } ssize_t written = write(fd, buffer, to_write); if (written < 0 ) { perror("write error" ); exit (EXIT_FAILURE); } written_bytes += written; } close(fd); return 0 ; }
使用 mmap 读取文件并统计行数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 #include <stdio.h> #include <stdlib.h> #include <fcntl.h> #include <sys/mman.h> #include <sys/stat.h> #include <unistd.h> #include <time.h> #include <string.h> int main (int argc, char *argv[]) if (argc != 2 ) { printf ("Usage: %s <file>\n" , argv[0 ]); return 1 ; } int fd = open(argv[1 ], O_RDONLY); if (fd < 0 ) { perror("open" ); return 1 ; } struct stat sb; if (fstat(fd, &sb) == -1 ) { perror("fstat" ); close(fd); return 1 ; } char *file_data = (char *)mmap(NULL , sb.st_size, PROT_READ, MAP_PRIVATE, fd, 0 ); if (file_data == MAP_FAILED) { perror("mmap" ); close(fd); return 1 ; } clock_t start = clock(); size_t line_count = 0 ; char *next = NULL ; for (char *current = file_data; current - file_data < sb.st_size; current = next + 1 ) { next = (char *)memchr (current, '\n' , sb.st_size - (current - file_data)); if (next) { line_count++; } else { break ; } } clock_t end = clock(); printf ("Line count: %zu\n" , line_count); printf ("Time taken: %lf ms\n" , (double )(end - start) / CLOCKS_PER_SEC * 1000 ); munmap(file_data, sb.st_size); close(fd); return 0 ; }
使用普通IO读取文件并统计行数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include <stdio.h> #include <stdlib.h> #include <fcntl.h> #include <sys/stat.h> #include <unistd.h> #include <time.h> int main (int argc, char *argv[]) if (argc != 2 ) { printf ("Usage: %s <file>\n" , argv[0 ]); return 1 ; } FILE *fp = fopen(argv[1 ], "r" ); if (!fp) { perror("fopen" ); return 1 ; } clock_t start = clock(); size_t line_count = 0 ; char *line = NULL ; size_t line_length = 0 ; ssize_t read_length; while ((read_length = getline(&line, &line_length, fp)) != -1 ) { line_count++; } clock_t end = clock(); printf ("Line count: %zu\n" , line_count); printf ("Time taken: %lf ms\n" , (double )(end - start) / CLOCKS_PER_SEC * 1000 ); free (line); fclose(fp); return 0 ; }
测试结果:
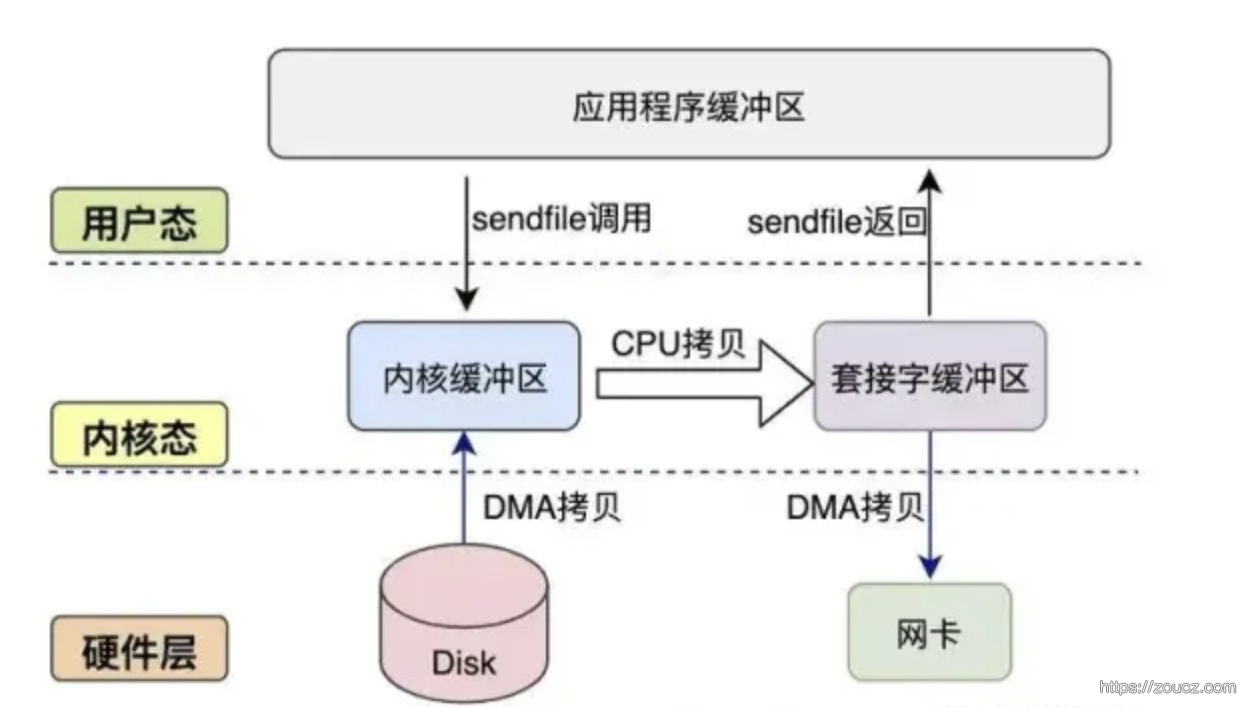
sendfile 概念和适用场景
sendfile 相当于实现了 mmap + write 的功能。该函数可以在两个文件描述符之间直接传输数据,避免了数据在用户空间和内核空间之间的拷贝,从而减少了一次从内核态到用户态的拷贝。
sendfile适用的场景:
文件服务器:在文件服务器中,常需要将磁盘上的文件发送给客户端。使用sendfile方法可以直接将数据从磁盘传输到套接字,避免了多余的数据拷贝操作,提高了文件传输的性能。
代理服务器:代理服务器需要将客户端的请求转发给目标服务器,并将目标服务器的响应返回给客户端。使用sendfile方法可以在套接字之间直接传输数据,提高了代理服务器的性能。
Web服务器:Web服务器需要将磁盘上的静态文件发送给客户端。使用sendfile方法可以提高文件传输的性能,降低服务器的资源消耗。
数据库服务器:数据库服务器需要将数据文件中的数据发送给客户端。使用sendfile方法可以提高数据传输的效率,降低服务器的资源消耗。
Nginx、Apache、Haproxy 等项目使用 sendfile 来提高文件传输性能。
示例代码 下面是两段测试代码,来测试 sendfile 和普通 IO 的性能差异,仍然使用上面创建的测试文件
使用 sendfile 读取文件并发送:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 #include <arpa/inet.h> #include <fcntl.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/sendfile.h> #include <sys/socket.h> #include <sys/stat.h> #include <sys/time.h> #include <unistd.h> int main (int argc, char * argv[]) if (argc != 2 ) { printf ("Usage: %s <file>\n" , argv[0 ]); return 1 ; } int server_fd, client_fd, file_fd; struct sockaddr_in server_addr, client_addr; socklen_t client_addr_len = sizeof (client_addr); struct stat file_stat; off_t offset = 0 ; ssize_t sent_bytes = 0 ; struct timeval start, end; server_fd = socket(AF_INET, SOCK_STREAM, 0 ); memset (&server_addr, 0 , sizeof (server_addr)); server_addr.sin_family = AF_INET; server_addr.sin_addr.s_addr = htonl(INADDR_ANY); server_addr.sin_port = htons(12345 ); bind(server_fd, (struct sockaddr *)&server_addr, sizeof (server_addr)); listen(server_fd, 1 ); client_fd = accept(server_fd, (struct sockaddr *)&client_addr, &client_addr_len); file_fd = open(argv[1 ], O_RDONLY); fstat(file_fd, &file_stat); gettimeofday(&start, NULL ); while (((sent_bytes = sendfile(client_fd, file_fd, &offset, file_stat.st_size)) > 0 ) && (file_stat.st_size > 0 )) { file_stat.st_size -= sent_bytes; } gettimeofday(&end, NULL ); long elapsed_ms = (end.tv_sec - start.tv_sec) * 1000 + (end.tv_usec - start.tv_usec) / 1000 ; printf ("sendfile: %ld ms\n" , elapsed_ms); close(file_fd); close(client_fd); close(server_fd); return 0 ; }
使用普通 IO 读取文件并发送:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 #include <arpa/inet.h> #include <fcntl.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <sys/stat.h> #include <sys/time.h> #include <unistd.h> #define BUFFER_SIZE 8192 int main (int argc, char * argv[]) if (argc != 2 ) { printf ("Usage: %s <file>\n" , argv[0 ]); return 1 ; } int server_fd, client_fd, file_fd; struct sockaddr_in server_addr, client_addr; socklen_t client_addr_len = sizeof (client_addr); struct stat file_stat; char buffer[BUFFER_SIZE]; ssize_t read_bytes, sent_bytes; struct timeval start, end; server_fd = socket(AF_INET, SOCK_STREAM, 0 ); memset (&server_addr, 0 , sizeof (server_addr)); server_addr.sin_family = AF_INET; server_addr.sin_addr.s_addr = htonl(INADDR_ANY); server_addr.sin_port = htons(12345 ); bind(server_fd, (struct sockaddr *)&server_addr, sizeof (server_addr)); listen(server_fd, 1 ); client_fd = accept(server_fd, (struct sockaddr *)&client_addr, &client_addr_len); file_fd = open(argv[1 ], O_RDONLY); fstat(file_fd, &file_stat); gettimeofday(&start, NULL ); while ((read_bytes = read(file_fd, buffer, BUFFER_SIZE)) > 0 ) { sent_bytes = 0 ; while (sent_bytes < read_bytes) { ssize_t sent = send(client_fd, buffer + sent_bytes, read_bytes - sent_bytes, 0 ); if (sent < 0 ) { perror("send error" ); exit (EXIT_FAILURE); } sent_bytes += sent; } } gettimeofday(&end, NULL ); long elapsed_ms = (end.tv_sec - start.tv_sec) * 1000 + (end.tv_usec - start.tv_usec) / 1000 ; printf ("regular IO: %ld ms\n" , elapsed_ms); close(file_fd); close(client_fd); close(server_fd); return 0 ; }
客户端:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #include <arpa/inet.h> #include <fcntl.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <unistd.h> #define BUFFER_SIZE 8192 int main () int client_fd; struct sockaddr_in server_addr; char buffer[BUFFER_SIZE]; ssize_t received_bytes; client_fd = socket(AF_INET, SOCK_STREAM, 0 ); memset (&server_addr, 0 , sizeof (server_addr)); server_addr.sin_family = AF_INET; server_addr.sin_addr.s_addr = inet_addr("127.0.0.1" ); server_addr.sin_port = htons(12345 ); connect(client_fd, (struct sockaddr *)&server_addr, sizeof (server_addr)); while ((received_bytes = recv(client_fd, buffer, BUFFER_SIZE, 0 )) > 0 ) { } close(client_fd); return 0 ; }
测试结果:
1 sendfile: 221 ms
regular IO: 499 ms
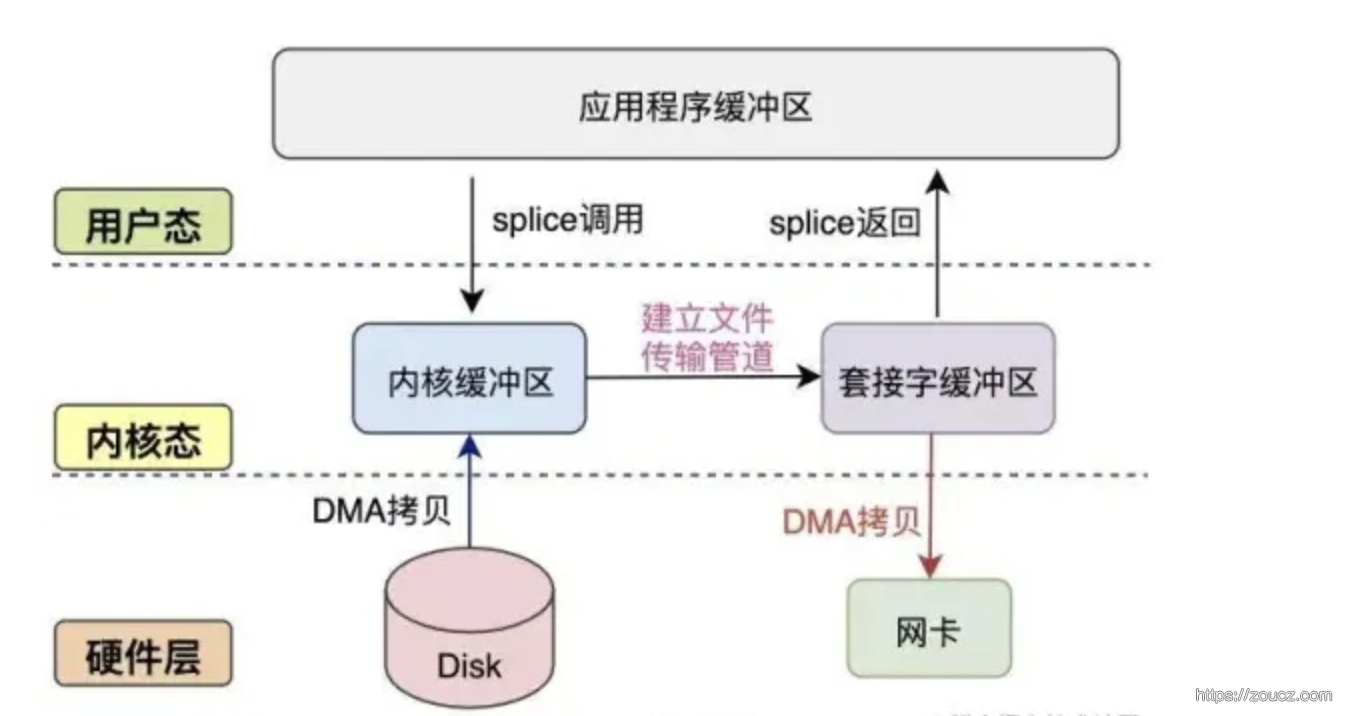
splice 概念和适用场景
和 sendfile 一样,该函数可以将数据从一个文件描述符移动到另一个文件描述符,而不需要将数据从内核态拷贝到用户态,减少了一次拷贝过程。
和 sendfile 的差异 splice 和 sendfile 都是用于优化数据传输的 Linux 系统调用,它们之间有一定的联系,但也有一些区别。
功能上的差异
sendfile 主要用于在两个文件描述符之间传输数据,特别是将文件数据发送到网络套接字。它可以在内核空间直接完成数据传输,避免了用户空间和内核空间之间的数据拷贝,从而提高了性能。然而,sendfile的一个限制是,它只能用于普通文件和套接字之间的数据传输。
splice 是一个更通用的数据传输系统调用,它可以在任意类型的文件描述符之间传输数据,包括普通文件、设备文件、套接字等。 splice 的工作原理是将数据从一个文件描述符移动到另一个文件描述符,而不需要将数据拷贝到用户空间。这样,它可以在内核空间完成数据传输,提高性能。与 sendfile 相比, splice 的优势在于它可以处理更多类型的文件描述符,更加灵活。
数据传输方式差异:
sendfile 在内核空间直接将数据从一个文件描述符传输到另一个文件描述符,不需要通过用户空间的缓冲区。sendfile适用于将磁盘上的文件发送到网络套接字的场景,例如文件服务器、Web服务器等。
splice 通过管道(pipe)在文件描述符之间传输数据。首先,它将数据从一个文件描述符移动到管道,然后将数据从管道移动到另一个文件描述符。这样,数据在内核空间完成传输,避免了用户空间和内核空间之间的数据拷贝。splice适用于各种类型的文件描述符之间的数据传输,例如设备文件、套接字等。
示例代码 使用 splice 读取文件并发送
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 #include <arpa/inet.h> #include <fcntl.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <sys/stat.h> #include <sys/time.h> #include <unistd.h> #define BUFFER_SIZE 8192 int main (int argc, char * argv[]) if (argc != 2 ) { printf ("Usage: %s <file>\n" , argv[0 ]); return 1 ; } int server_fd, client_fd, file_fd; struct sockaddr_in server_addr, client_addr; socklen_t client_addr_len = sizeof (client_addr); struct stat file_stat; int pipe_fds[2 ]; ssize_t splice_bytes; struct timeval start, end; server_fd = socket(AF_INET, SOCK_STREAM, 0 ); memset (&server_addr, 0 , sizeof (server_addr)); server_addr.sin_family = AF_INET; server_addr.sin_addr.s_addr = htonl(INADDR_ANY); server_addr.sin_port = htons(12345 ); bind(server_fd, (struct sockaddr *)&server_addr, sizeof (server_addr)); listen(server_fd, 1 ); client_fd = accept(server_fd, (struct sockaddr *)&client_addr, &client_addr_len); file_fd = open(argv[1 ], O_RDONLY); fstat(file_fd, &file_stat); pipe(pipe_fds); gettimeofday(&start, NULL ); while ((splice_bytes = splice(file_fd, NULL , pipe_fds[1 ], NULL , BUFFER_SIZE, SPLICE_F_MOVE)) > 0 ) { splice(pipe_fds[0 ], NULL , client_fd, NULL , splice_bytes, SPLICE_F_MOVE); } gettimeofday(&end, NULL ); long elapsed_ms = (end.tv_sec - start.tv_sec) * 1000 + (end.tv_usec - start.tv_usec) / 1000 ; printf ("splice: %ld ms\n" , elapsed_ms); close(file_fd); close(client_fd); close(server_fd); return 0 ; }
使用普通 IO 读取文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 #include <arpa/inet.h> #include <fcntl.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <sys/stat.h> #include <sys/time.h> #include <unistd.h> #define BUFFER_SIZE 8192 int main (int argc, char * argv[]) if (argc != 2 ) { printf ("Usage: %s <file>\n" , argv[0 ]); return 1 ; } int server_fd, client_fd, file_fd; struct sockaddr_in server_addr, client_addr; socklen_t client_addr_len = sizeof (client_addr); struct stat file_stat; char buffer[BUFFER_SIZE]; ssize_t read_bytes, sent_bytes; struct timeval start, end; server_fd = socket(AF_INET, SOCK_STREAM, 0 ); memset (&server_addr, 0 , sizeof (server_addr)); server_addr.sin_family = AF_INET; server_addr.sin_addr.s_addr = htonl(INADDR_ANY); server_addr.sin_port = htons(12345 ); bind(server_fd, (struct sockaddr *)&server_addr, sizeof (server_addr)); listen(server_fd, 1 ); client_fd = accept(server_fd, (struct sockaddr *)&client_addr, &client_addr_len); file_fd = open(argv[1 ], O_RDONLY); fstat(file_fd, &file_stat); gettimeofday(&start, NULL ); while ((read_bytes = read(file_fd, buffer, BUFFER_SIZE)) > 0 ) { sent_bytes = 0 ; while (sent_bytes < read_bytes) { ssize_t sent = send(client_fd, buffer + sent_bytes, read_bytes - sent_bytes, 0 ); if (sent < 0 ) { perror("send error" ); exit (EXIT_FAILURE); } sent_bytes += sent; } } gettimeofday(&end, NULL ); long elapsed_ms = (end.tv_sec - start.tv_sec) * 1000 + (end.tv_usec - start.tv_usec) / 1000 ; printf ("regular IO: %ld ms\n" , elapsed_ms); close(file_fd); close(client_fd); close(server_fd); return 0 ; }
测试结果:
1 splice: 224 ms
regular IO: 473 ms
Direct IO 概念 Direct IO 是一种在文件系统层面实现的绕过内核缓存的技术。Direct IO 仍然使用文件系统,但是在读写文件时,数据直接从磁盘传输到用户空间,而不经过内核缓存。
需要注意的是,不经过内核缓存,对于单次的文件读写来说,性能反而会下降。在某些大文件高并发读写场景下,可以通过开启 Direct IO 配合 aio,减小 IO 过程中的 CPU 和内存开销,从而提升整体性能。
示例代码 仍然使用前面创建的 test_data.txt 做测试。测试单次文件读写的性能,可以发现实际上 directio 比普通的 IO 速度是更慢的。
使用 direct io 读取文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 #include <stdio.h> #include <stdlib.h> #include <fcntl.h> #include <sys/stat.h> #include <unistd.h> #include <time.h> #include <errno.h> #ifndef O_DIRECT #define O_DIRECT 040000 #endif #define BUF_SIZE 1024 int main (int argc, char *argv[]) if (argc != 2 ) { printf ("Usage: %s <file>\n" , argv[0 ]); return 1 ; } int fd = open(argv[1 ], O_RDONLY | O_DIRECT); if (fd < 0 ) { perror("open" ); return 1 ; } char *buf; if (posix_memalign((void **)&buf, BUF_SIZE, BUF_SIZE) != 0 ) { perror("posix_memalign" ); close(fd); return 1 ; } clock_t start = clock(); size_t total_bytes = 0 ; ssize_t read_length; while ((read_length = read(fd, buf, BUF_SIZE)) > 0 ) { total_bytes += read_length; } clock_t end = clock(); if (read_length < 0 ) { perror("read" ); } printf ("Total bytes: %zu\n" , total_bytes); printf ("Time taken: %lf ms\n" , (double ) (end - start) / CLOCKS_PER_SEC * 1000 ); free (buf); close(fd); return 0 ; }
使用普通 io 读取文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include <stdio.h> #include <stdlib.h> #include <fcntl.h> #include <sys/stat.h> #include <unistd.h> #include <time.h> #define BUF_SIZE 1024 int main (int argc, char *argv[]) if (argc != 2 ) { printf ("Usage: %s <file>\n" , argv[0 ]); return 1 ; } FILE *fp = fopen(argv[1 ], "r" ); if (!fp) { perror("fopen" ); return 1 ; } char buf[BUF_SIZE]; clock_t start = clock(); size_t total_bytes = 0 ; ssize_t read_length; while ((read_length = fread(buf, 1 , BUF_SIZE, fp)) > 0 ) { total_bytes += read_length; } clock_t end = clock(); printf ("Total bytes: %zu\n" , total_bytes); printf ("Time taken: %lf ms\n" , (double ) (end - start) / CLOCKS_PER_SEC * 1000 ); fclose(fp); return 0 ; }
测试结果:
1 Direct IO:
Total bytes: 1073741824
Time taken: 9720.000000 ms
regular IO:
Total bytes: 1073741824
Time taken: 250.000000 ms
其它 IO 优化相关技术 写时复制 Linux的写时复制(Copy-on-Write)机制是指在进程创建子进程或者读取文件内容时,并不会立即将数据完全复制到新的地址空间中。而是通过共享同一段物理内存来提高效率。只有当其中一个进程对该部分数据进行修改时,才会真正发生复制操作。
这种技术可以避免大量无用的数据复制,节省了系统开销。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/mman.h> #include <sys/wait.h> #include <unistd.h> int main () const size_t data_size = 4096 ; int status; char shared_data[] = "Hello, copy-on-write!" ; pid_t pid = fork(); if (pid < 0 ) { perror("fork error" ); exit (EXIT_FAILURE); } if (pid == 0 ) { printf ("Child process: initial data: %s\n" , shared_data); shared_data[0 ] = 'h' ; printf ("Child process: modified data: %s\n" , shared_data); exit (EXIT_SUCCESS); } else { waitpid(pid, &status, 0 ); printf ("Parent process: data: %s\n" , shared_data); } return 0 ; }
测试结果:
1 Child process: initial data: Hello, copy-on-write!
Child process: modified data: hello, copy-on-write!
Parent process: data: Hello, copy-on-write!
RDMA(Remote Direct Memory Access) RDMA( Remote Direct Memory Access )意为远程直接地址访问,通过RDMA,本端节点可以“直接”访问远端节点的内存。所谓直接,指的是可以像访问本地内存一样,绕过传统以太网复杂的TCP/IP网络协议栈读写远端内存,而这个过程对端是不感知的,而且这个读写过程的大部分工作是由硬件而不是软件完成的。
需要专门的硬件(网卡)支持。
参考: https://zhuanlan.zhihu.com/p/138874738
DPDK(Data Plane Development Kit) Data Plane Development Kit 是运行在用户空间上利用自身提供的数据平面库来收发数据包,绕过了 Linux 内核协议栈对数据包处理过程。在收到数据包时,经DPDK重载的网卡驱动不会通过中断通知CPU,而是直接将数据包存入内存,交付应用层软件通过DPDK提供的接口来直接处理,这样节省了大量的CPU中断时间和内存拷贝时间。
参考: https://zhuanlan.zhihu.com/p/632045322
SPDK SPDK(Storage Performance Development Kit),包含一套驱动程序,以及一整套端到端的存储参考架构。SPDK的目标是能够把硬件平台的计算、网络、存储(基于 NVME 的高读写性能 ssd 磁盘)的最新性能进展充分发挥出来。自芯片而上进行设计优化,SPDK 已展示出超高的性能指标。
它的高性能实际上来自于两项核心技术:第一个是用户态运行,第二个是轮询模式驱动。
参考: https://zhuanlan.zhihu.com/p/646710218
参考文档:
本文链接:https://www.zoucz.com/blog/2023/12/31/93b6dc00-a7c3-11ee-95cb-3556e1632a5e/