一次tars c++服务性能问题排查经历 —— 网络与CPU分析
1. 背景
去年有做一个项目,将一套tars服务迁移,跑在公司的云上k8s集群上,并在云上集群部署了100并发的资源,压测验证OK。
按业务计划,后续要开始使用1000并发级别的资源,于是提前两周开始扩容千并发资源并压测。
忙前忙后协调好了资源,和同事一起把服务部署好,本来准备压测一把完事的,结果意外出现了:千并发资源的集群,竟然压测到200并发不到的时候就跪了,具体表现为绝大部分片包、尾包在客户端超时。
和同事一起查了许久,直到最终解决问题,过程中走了一些弯路,也积累了一些经验,做了一个总结。
想来这是一次不错的性能问题排查经验,在自己的blog里边也同步一份吧。
2. Proxy服务网络问题排查
对于此结果,我之前是有过经验的——在工作机上往213环境压测,由于上行带宽限制比较小(8Mbps?),压测并发数根本就上不去,会因为带宽吃满而延时极大,客户端超时。
2.1 带宽分析
既然200并发都上不去,那么计算一下200并发大致所需带宽:
1 | 6400byte每次请求 * 5次请求/s * 200并发 * ≈ 50Mbps |
说实话,并不大。
在压测机器上 ping一把:
1 | PING xxx.xxx.xxx.xxx (xxx.xxx.xxx.xxx) 56(84) bytes of data. 64 bytes from xxx.xxx.xxx.xxx: icmp_seq=1 ttl=52 time=33.0 ms 64 bytes from xxx.xxx.xxx.xxx: icmp_seq=2 ttl=52 time=33.0 ms 64 bytes from xxx.xxx.xxx.xxx: icmp_seq=3 ttl=52 time=32.9 ms |
相对于深圳→深圳,这个深圳→南京的延时挺高.
traceroute一把:
1 | [running]mqq@:~$ traceroute x.xxx.123.149 12800 traceroute to x.xxx.123.149 (x.xxx.123.149), 30 hops max, 12800 byte packets 1 x.xxx.152.193 (x.xxx.152.193) 3.175 ms 4.507 ms 6.207 ms 2 x.xxx.105.242 (x.xxx.105.242) 5.680 ms 5.783 ms 5.859 ms 3 x.xxx.184.174 (x.xxx.184.174) 1.130 ms 3.723 ms 6.107 ms 4 x.xxx.2.101 (x.xxx.2.101) 5.987 ms x.xxx.2.37 (x.xxx.2.37) 1.983 ms x.xxx.2.101 (x.xxx.2.101) 2.174 ms 5 x.xxx.14.73 (x.xxx.14.73) 0.618 ms 100.126.14.69 (x.xxx.14.69) 1.987 ms 1.309 ms 6 * * * 7 * * * 8 * * * 9 * x.xxx.33.234 (x.xxx.33.234) 31.874 ms * 10 * * * 11 * x.xxx.225.105 (x.xxx.225.105) 40.719 ms * 12 x.xxx.52.73 (x.xxx.52.73) 32.648 ms x.xxx.116.87 (x.xxx.116.87) 49.498 ms * 13 * * * 14 * * * 15 * * * 16 * * * 17 * * * 18 x.xxx.123.149 (x.xxx.123.149) 32.856 ms 32.965 ms 32.830 ms |
中间网关挺多,速度也不快。
有理由怀疑是不是中间某个网关带宽不够,导致压测时延时不断增大,最终超时。
联系了运维助手,表示不太会是这种情况。另外上网查了下,使用 iperf 工具,分析了下带宽.
1 | yum install -y iperf 服务端 iperf -s 客户端 iperf -c 服务端ip |
最终得到的结果: 3.2Gbps ,相对于压测所需的 50Mbps,大了几个数量级了,排除带宽原因。
2.2 TCP报文分析
带宽没问题,排查停滞了,接下来怎么办呢?
对于这种必现的问题,考虑单case分析,延时长,那么就拿出一条实例来,看看为什么长。
200并发压起来,出现了大量超时,ok,拿出一条session,去查一下链路上报日志:
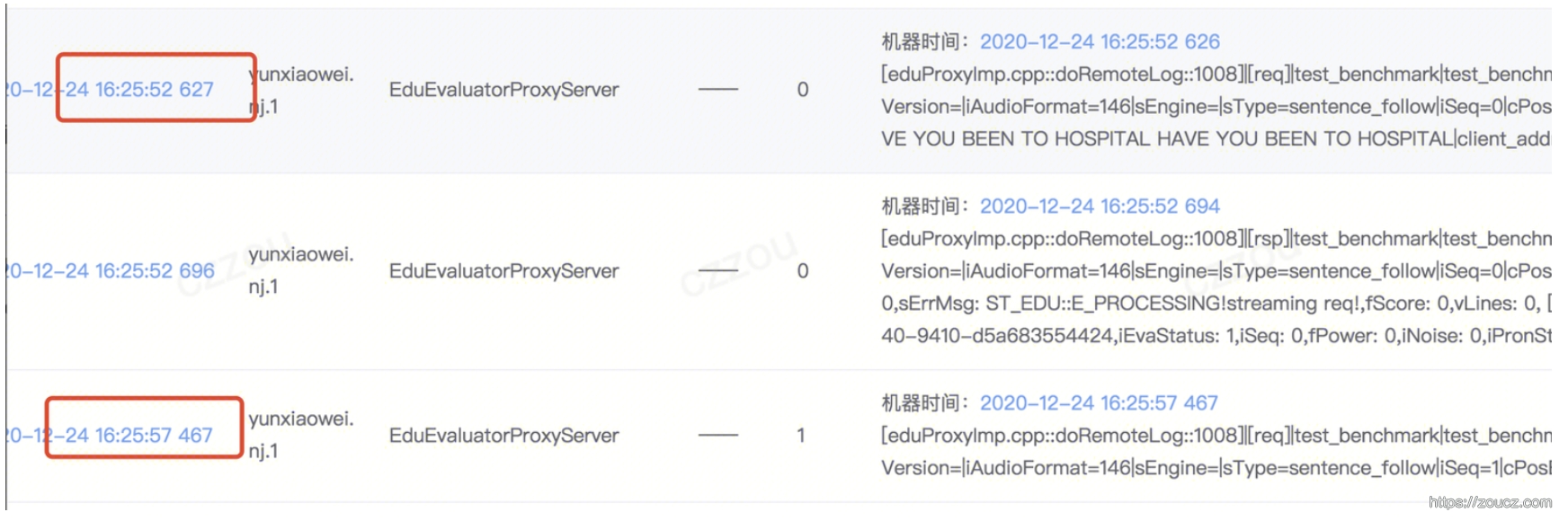
可以石锤,片包和片包之间的时间间隔非常大,而客户端压测程序发包,是200ms一片发送,返回后计算时间,至少间隔200ms发送下一片。
那么就有两种情况.
①网络传输延时大,导致片包间隔大.
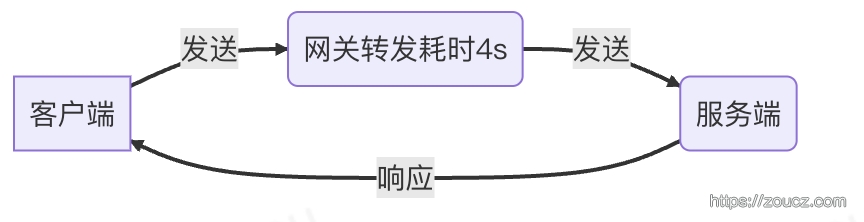
②服务端处理慢,导致片包间隔大.
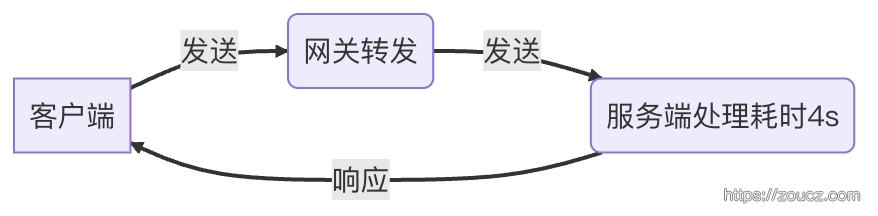
对于情况①,看ping值挺稳定的,也不丢包,带宽也够,不像;对于情况②,查看链路上报日志,处理时间都很快,不像。
继续分析单条。200并发压起来,出现超时,然后单独启动一个1并发的压测程序,用 tcpdump 单独对其抓包,分析其报文。
1 | 1. ps -ef|grep ts-node 查看PID 2. lsof -p 进程ID -nP | grep TCP 查看本地端口 3. sudo tcpdump -i eth1 -s 68 -nn -vvv port 本地端口 host 远端IP -w ./client.cap (对于同一条连接,同时在客户端、服务端分别抓包) |
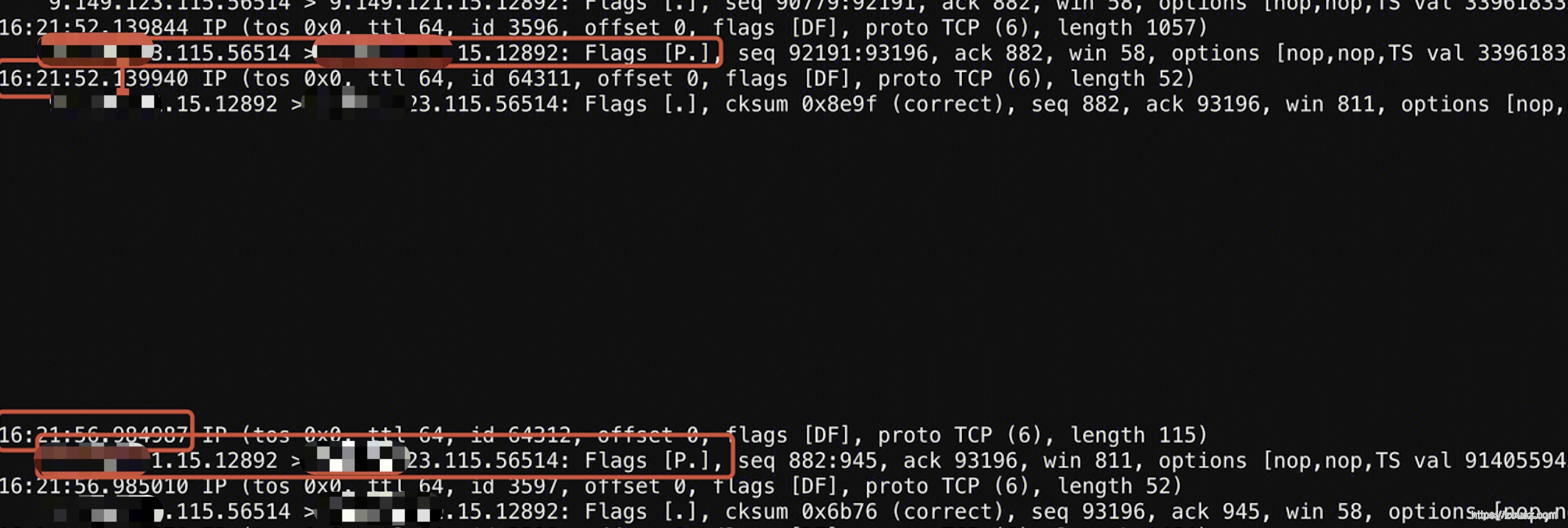
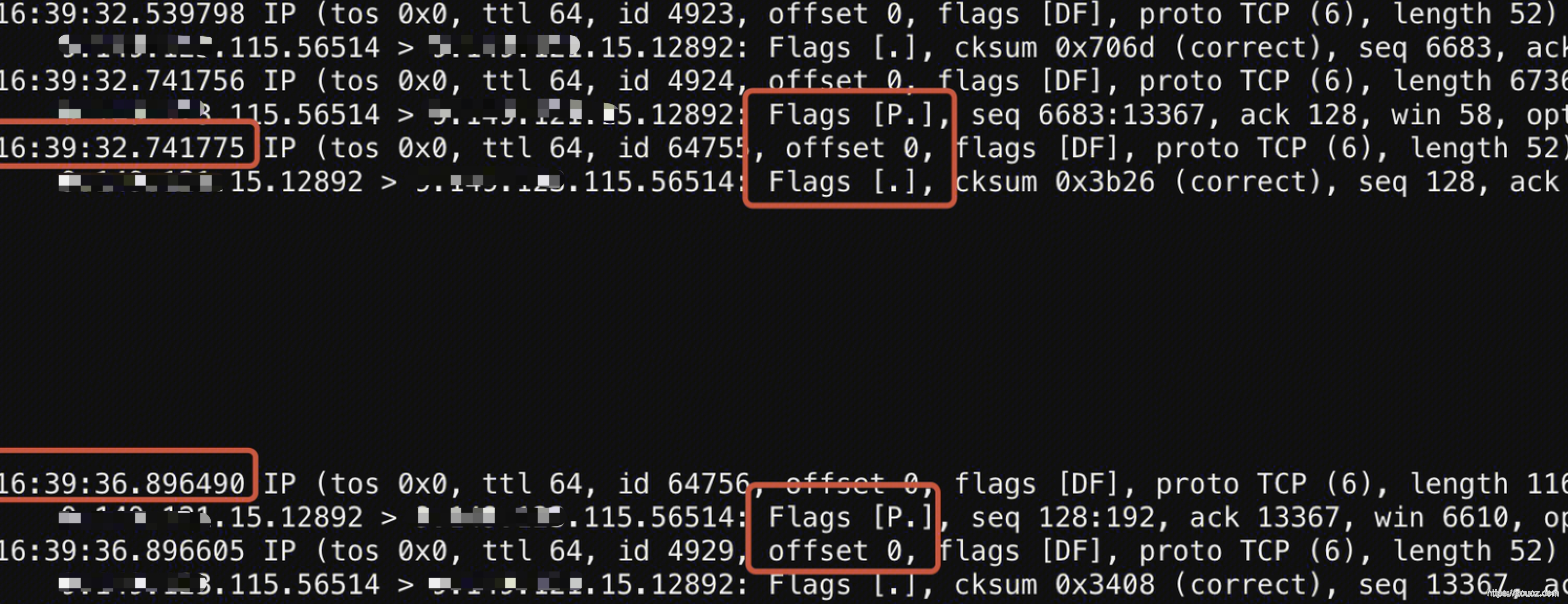
服务端抓包结果:被调收到的早、被调发送的迟4s。
到这里问题已经出现端倪,浮出纸面了 —— 日志显示处理的飞快、带宽足够、结果开始发送很慢。
2.3 修复Proxy服务问题
tars cpp rpc server处理请求的流程:

既然1不慢、3不慢、4不慢,那慢的肯定就是2了。
查看队列特性上报
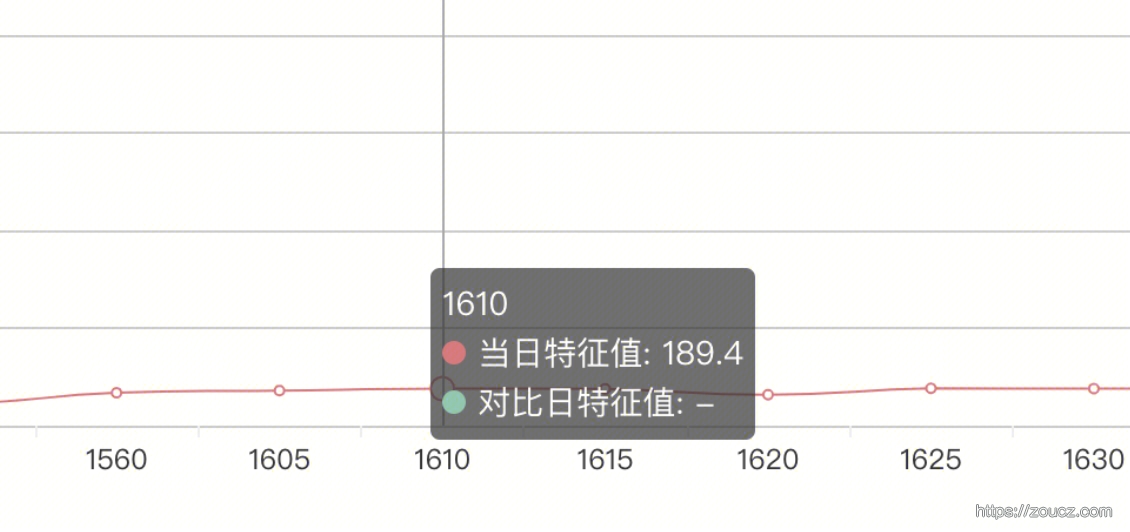
果然,队列堆积很多,导致排队时间过长,看起来处理很快实际上整个耗时很长。
最头前的 Proxy 服务产生队列堆积,那只可能是流程没有异步化。检查配置,果然私有模板中没开启协程,原因是制作tars-stke上的业务镜像时,私有模板路径的环境变量忘配置了。
有点坑自己的感觉,不过排查问题的过程和方法,还是能一步一步最终走向真相,值得记录。
重新制作镜像,重建pod,再200并发怼起来,果然 —— 以之前同样的姿势跪了。
3. Asr Kaldi服务 CPU问题排查
开启Proxy服务协程后,可以看到Proxy处堆积的队列已经没了,但是响应还是很慢。
查看各个服务的监控和日志后发现,asrkaldisercer处理速度极慢,超时率极高,CPU占用极高。
经过一通分析,这就有点没道理了,南京集群和线上 abcmouse 所使用的广州集群,一模一样的CPU型号、核数、镜像、业务代码&配置,为啥表现差异那么大?

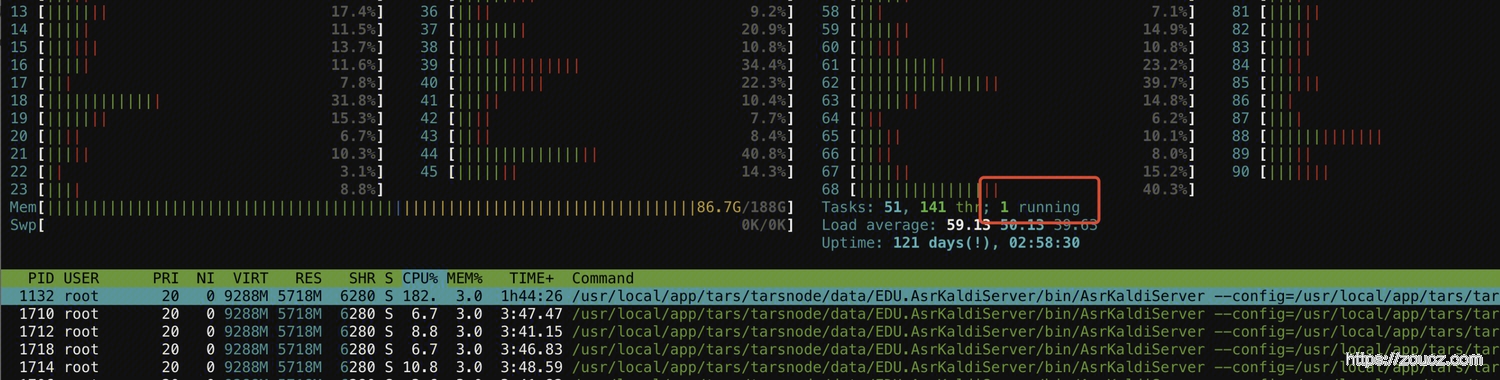
由于广州已经有线上流量了,找了个正常的深圳集群,AMD的CPU,running稳定在1,6并发CPU吃了2核左右。
从腾讯云助手处得知,南京云为eks集群,其它地区为tke集群。但是这也只能知道他们确实有差异而已,助手自身以及拉的一个20人群,也没人能说清楚为什么。
所以现在只能从唯一的变量——CPU占用 来下手, 好在,这是个必现的问题。
3.1 解码器线程数 & MKL线程数调整
在业务配置文件中修改解码器线程数,压测分析
在私有模板环境变量中调整MKL线程数 MKL_NUM_THREADS=1,压测分析
均无变化
3.2 MKL库CPU指令集调整
年初去上海给某客户做私有化部署时,曾经解决过类似问题,当时是通过调整MKL库的CPU指令集解决了类似的性能问题,将指令集由avx512调整到avx2,缩小每并发处理的size,能获得更好的计算性能。
查看cpu支持哪些指令集
1 | cat /proc/cpuinfo |

从flags中可以看到本机CPU支持的功能,里边有avx2也有avx512
查看服务进程使用的是哪个指令集的mkl
1 | cat /proc/进程id/maps|grep avx |

在私有模板中修改mkl指令集
1 | env=LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/root/anaconda2/lib;MKL_ENABLE_INSTRUCTIONS=AVX2 |
这里最开始是avx512, 我修改后这里可以看到是avx2。
压测,还是有问题,看来不是指令集的问题。
3.3 cpu perf && 火焰图
开始对比正常集群和南京集群的CPU消耗有什么区别。
200并发同时对深圳、南京集群压起来。
分别抓取CPU执行任务记录
1 | perf record -F 99 -p 进程ID -g -- sleep 30 |
用 perf report 进行报告分析

南京集群 ↑
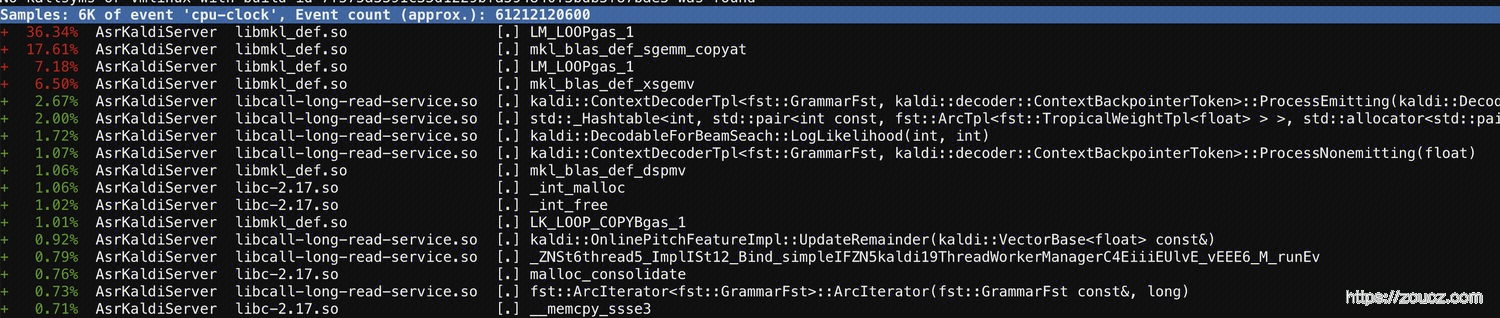
深圳集群 ↑
可以很明显的看到,南京集群不对劲, 深圳的CPU都用来干正事了——调用mkl库做计算。而南京的不知道拿来干啥了,so库中的逻辑。
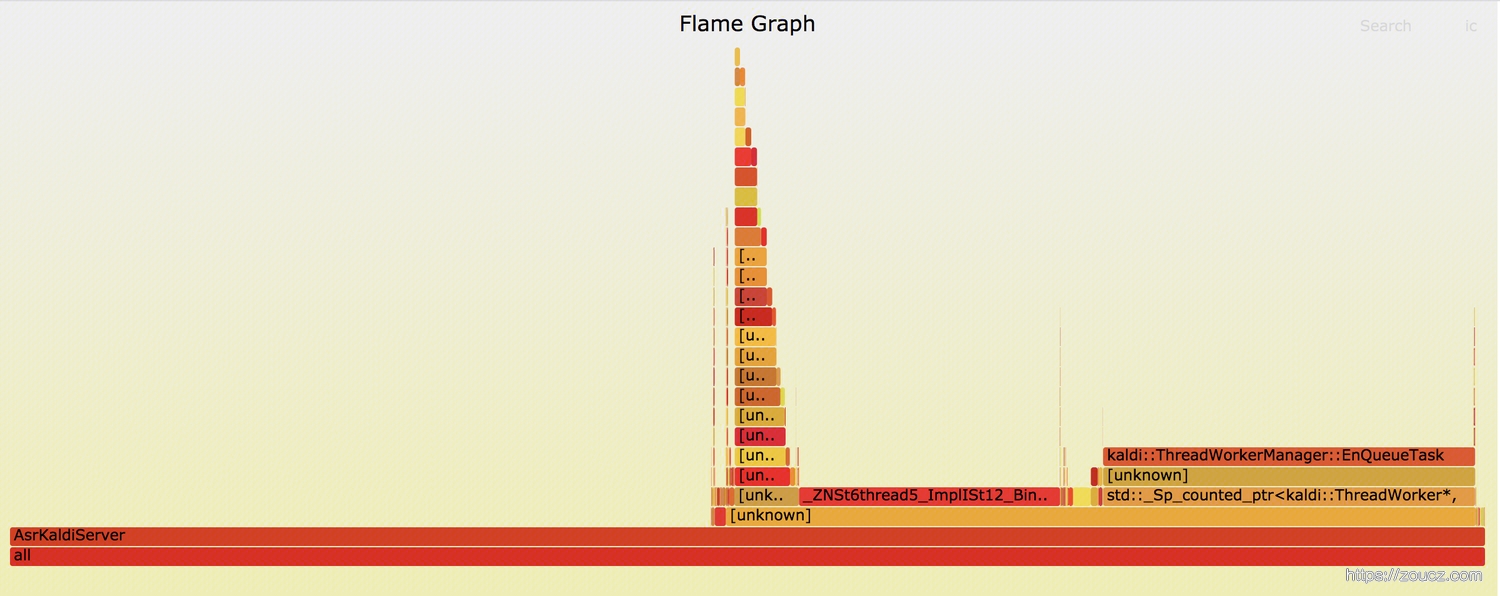
通过 FlameGraph 工具 生成南京集群CPU的火焰图。火焰图是一个svg文件,通过chrome打开文件,可以点击交互查看各个层级。
图中平顶的部分代表着可能存在性能瓶颈,点开后发现,一个是 ThreadWorkerManager中的runEnv,一个是 kaldi::ThreadWorkerManager::EnQueueTask。
3.4 代码分析
明确了问题可能出在哪,就可以开始翻代码了,这个是kaldiwrapper动态库里边的代码,有性能瓶颈的地方其实没有做任何操作疑似runEnv的地方
1 | { |
EnQueueTask函数
1 | bool ThreadWorkerManager::EnQueueTask(WorkerID id, TaskInfo task_info) { |
除了锁,没有任何造成阻塞吃CPU的地方。这里的锁如果是 std::mutex,也不会有任何问题,即使一直锁住,线程也会进入内核态,不会吃满CPU。
这里注意到,锁类型是 MutexType,不是 std::mutex,最终使用的锁是自己基于原子量实现的一个自旋锁
1 | class SpinLock { |
那么问题就初现端倪了,自旋锁由于始终处在用户态中,不会让出CPU,在某些情况下是有可能吃满CPU的。
在一些场景下,自旋锁由于其能够省掉线程上下文切换的开销(单次耗时最高可达0.06ms),在一些性能极度敏感的场景下,能带来一些性能提升。
但是这个东西,多位c++大牛都表示过非专家难以控制。它可能受服务器硬件、操作系统、编译器、业务代码等多种因素影响。要对c++并发编程、memory order有非常深入的了解,可能才能充分的玩转它。
那么到底是不是它出问题了呢,可以用perf工具继续验证。
3.4 perf调用关系
还是使用 perf report,查看代码的调用图
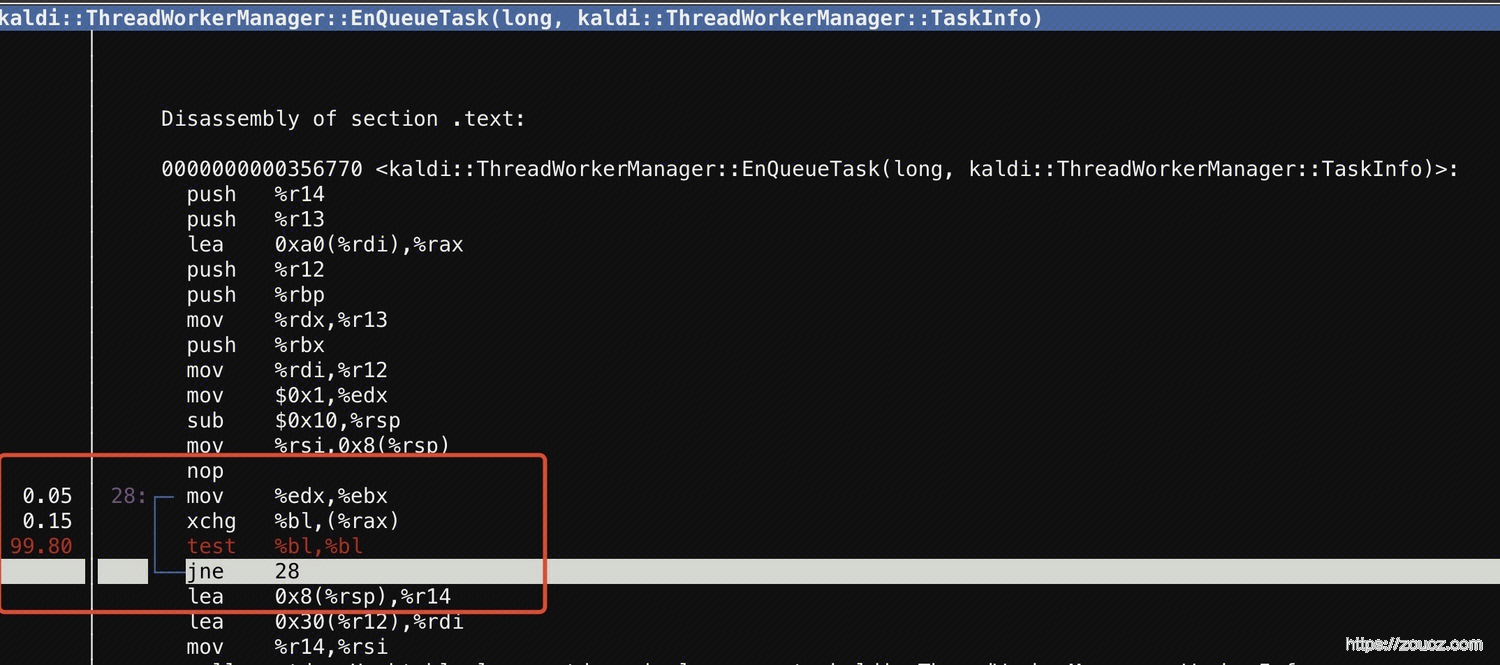
通过工具能看到一些汇编调用顺序,下面还有部分标准库函数打出了函数名(没截出来)
能发现,有一个循环里边的test逻辑,占用了全部CPU,前后对比代码定位,应该属于下面一段逻辑
1 | void lock() { |
比较明显了,应该就是由于某些未知的原因,导致自旋锁锁住的逻辑耗时边长,自旋锁长时间处于用户态,吃满CPU。从压测程序表现上来看,就是请求处理响应慢。
3.5 修复自旋锁问题
将自旋锁替换为 std::mutex,自定义条件变量 std::condition_variable_any 替换为 std::condition_variable,重新压测。

60并发,16核的CPU吃了11核,70%+。
貌似不仅解决了问题,还带来了2倍的性能提升。上深圳集群验证,也是如此。
通过 perf stat 对比修改前后的统计指标
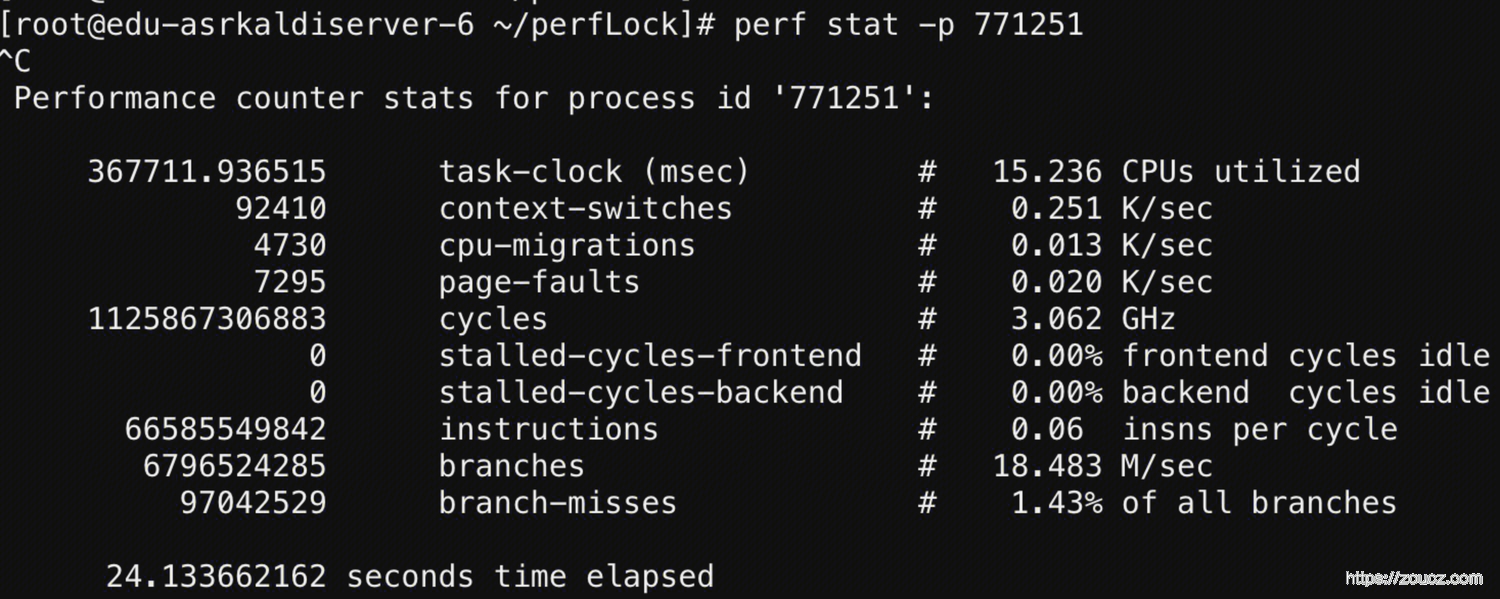
修改前 ↑
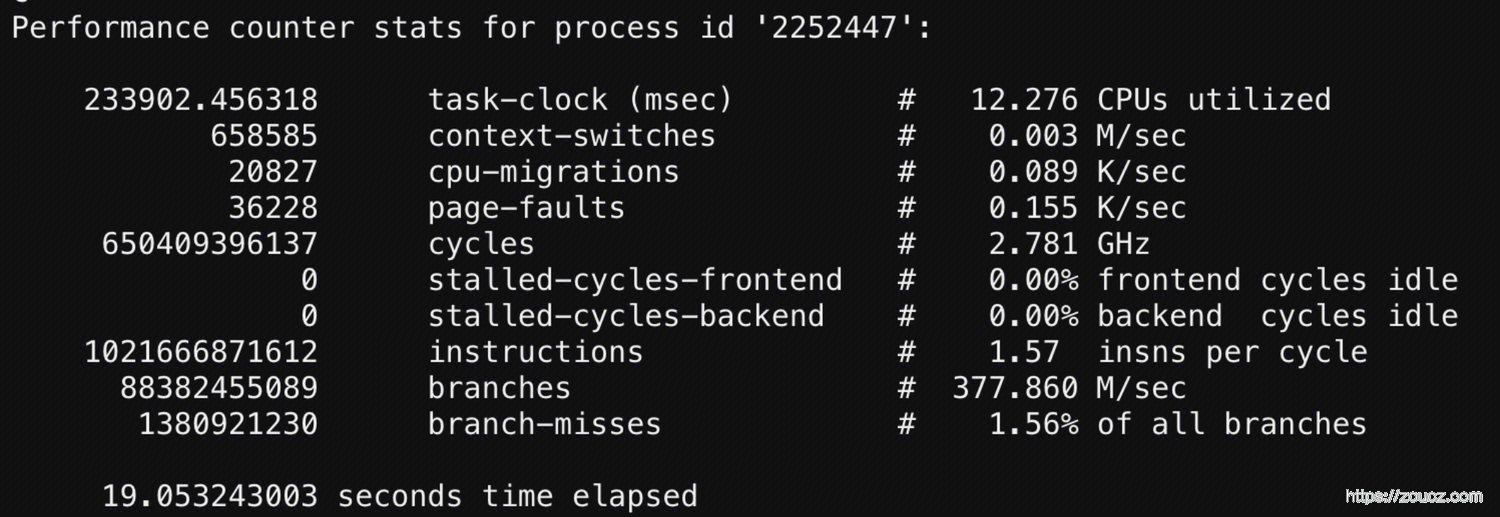
修改后 ↑
对比不是很严谨,但是可以很明显的发现,修改后上下文切换(context-switches)的开销变大了。
但是相对于声学服务涉及的大量计算,这里的线程上下文切换带来的开销可以忽略不计。
4. 后续
此处当时引入自旋锁应该是有原因的,因为它通过节省上下文切换开销确实是能带来一定程度的性能提升。只是由于某些未知的原因,这里反而导致了性能的下降。
后续可能的优化方向
- 参考《C++ Concurrency in Action》尝试把这个问题的原因搞明白,最终换回自旋锁。
- 较新的编译器会对std::mutex做优化,在某些情况下不做内核态切换,性能对齐自旋锁。
- proxy→logic→acoproxy→asrkaldi→feature,缺少从整个链路上成体系的过载保护和降级策略等,这里后续需要花时间来逐环节压测、调整代码或者配置。
本文链接:https://www.zoucz.com/blog/2021/06/20/a596cf30-d1d7-11eb-9fe7-534bbf9f369d/
