机器学习中的音频处理:滤波器组、MFCCS
本文为翻译理解文章,原文地址。
语音处理在任何语音系统中都有着非常重要的作用,无论是自动语音识别(ASR)还是说话人识别,还是其它领域。Mel-Frequency Cepstral Coefficients(MFCC)在很长一段时间内都是一个非常流行的特征,但是后来,滤波器组变得越来越受欢迎。本文将探讨滤波器组和MFCC的原理,以及为什么滤波器组变得越来越流行。
滤波器组和MFCC计算的过程有些相同,两者都是需要计算滤波器组的,在滤波器组结果上增加几个额外的步骤就可以获得MFCC特征。
简而言之:
1.声音信号先经过前置强化滤波器;
2.然后被分割成重叠帧,并对每个帧应用窗口函数;
3.然后,对每一帧进行傅立叶变换(更具体地说是短时傅立叶变换),计算功率谱;
4.然后计算滤波器组。
5.为了获得MFCC特征,对滤波器组进行离散余弦变换(DCT),保留一部分得到的系数,其余的系数被丢弃。
对于这两种特征,最后一步的计算都是做一次均值标准化。
1.初始化数据
本文中使用了一个16位的PCM wav文件,“osr_us_000_0010_8k.wav”,采样频率为8000 Hz,文件可以从这里获取。这个wav文件是一段干净无噪声的语音信号,内容是中间有停顿的一些句子。为了简单起见,使用了信号的前3.5秒,这大致相当于wav文件中的第一句话。
本文使用Python 2.7.x(译者决定用py3)、NumPy和SciPy。一些相关的代码可以在这个repository中找到。
import numpy
import scipy.io.wavfile
from scipy.fftpack import dct
import matplotlib.pyplot as plt
import librosa
import librosa.display
sample_rate, signal = scipy.io.wavfile.read('OSR_us_000_0010_8k.wav') # File assumed to be in the same directory
print(sample_rate, signal, signal.shape)
signal = signal[0:int(3.5 * sample_rate)] # Keep the first 3.5 seconds
plt.figure(figsize=(8, 2))
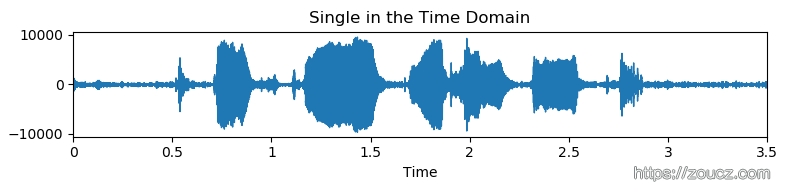
librosa.display.waveplot(signal/1, sample_rate)
plt.title("Single in the Time Domain")
plt.tight_layout()
plt.show()
这个代码中为了方便使用了librosa库的display函数来绘图,实际上librosa是可以直接计算mfcc特征的,这里为了分析过程只用它来做展示。
sci load出来的采样点数据是采样点原始数据,而librosa则返回根据比特率对应最大值归一化后的float数值。如本例中sci返回第一个采样点数据:-919,librosa返回第一个采样点:-919/2**15 = -0.02804565
2.预强化滤波器
使用预强化滤波器的第一步是强化高频信号,预强化滤波器的左右在于:(1)平衡频谱,因为高频信号通常比低频信号小;(2)避免了傅里叶变换过程中的数值问题;(3)可以提高信噪比(SNR)。
预强化滤波器对一个采样点数据x应用以下方程的一阶滤波器: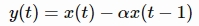
可以使用下面的代码很简单的实现,其中滤波系数α的典型值为0.95或0.97,PRE_DESSINCE=0.97:
emphasized_signal = numpy.append(signal[0], signal[1:] - pre_emphasis * signal[:-1])
在时下最新的系统中,预强化的作用不大,主要是因为除了避免傅立叶变换的数值问题之外,大多数预强化滤波器的目标都可以用均值归一化来实现(本文后面将讨论),而这个数值问题在现代的快速傅里叶变换计算中不再是一个问题。
下面是预强化之后的时域数据: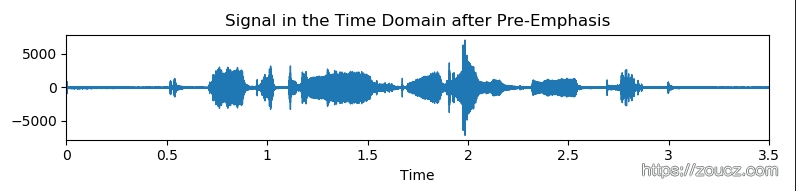
3.分帧
在预强化后,我们需要将信号分成一系列短时间的帧。这一步处理的原因是,音频信号中的频率会随着时间变化,因此在大多数情况下,对整个信号进行傅里叶变换是没有意义的,因为随着时间的推移,我们将丢失一些信号的频率随时间变化的特征。为了避免这种情况,我们可以大胆地假设信号中的频率在极短的时间内是稳定的。因此,通过在这一短时间帧上进行傅立叶变换,我们可以通过级联相邻帧来获得信号的频率概况的一个很好的近似值。
语音处理中典型的帧大小从20ms到40ms不等,连续帧之间的重叠率为50%(+/-10%)。
帧大小的常用设置为25ms,即frame_size=0.025,步幅为10ms(重叠部分为15ms),即frame_stride=0.01。
可以使用下面的代码给数据分帧:
# Convert from seconds to samples
frame_length, frame_step = frame_size * sample_rate, frame_stride * sample_rate
signal_length = len(emphasized_signal)
frame_length = int(round(frame_length))
frame_step = int(round(frame_step))
# Make sure that we have at least 1 frame
num_frames = int(numpy.ceil(float(numpy.abs(signal_length - frame_length)) / frame_step))
pad_signal_length = num_frames * frame_step + frame_length
z = numpy.zeros((pad_signal_length - signal_length))
# Pad Signal to make sure that all frames have equal number of samples
# without truncating any samples from the original signal
pad_signal = numpy.append(emphasized_signal, z)
indices = numpy.tile(numpy.arange(0, frame_length), (num_frames, 1)) + numpy.tile(numpy.arange(0, num_frames * frame_step, frame_step), (frame_length, 1)).T
frames = pad_signal[indices.astype(numpy.int32, copy=False)]
4.窗口函数
在将信号分成帧后,我们对每一帧应用一个窗口函数,如Hamming窗口。Hamming窗口具有以下形式:
其中0≤n≤N−1 N是窗口长度,窗口内位于n位置的采样点数值会应用w[n]作为权重值。
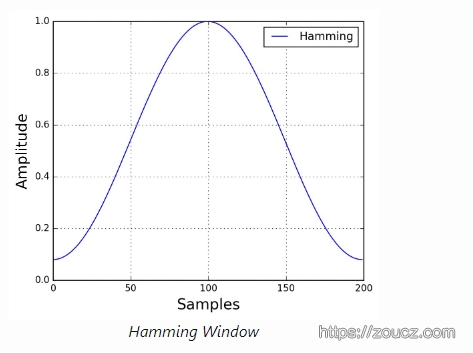
应用一个窗口函数的原因有几个,尤其是是抵消了快速傅里叶变化关于数据是无限的假设,并减少了频谱泄漏。
frames *= numpy.hamming(frame_length)
# frames *= 0.54 - 0.46 * numpy.cos((2 * numpy.pi * n) / (frame_length - 1)) # Explicit Implementation **
5.傅里叶变换和功率谱
对每一帧执行N点采样的快速傅里叶变换(FFT)来计算频谱(也称为短时傅立叶变换(STFT)),其中N通常为256或512,NFFT=512,表示在频域上的采样点个数。快速傅里叶变换计算完成后,使用以下公式计算功率谱(周期图):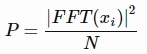
其中xi代表信号x的第i个frame,上面的计算可以用以下代码完成:
mag_frames = numpy.absolute(numpy.fft.rfft(frames, NFFT)) # Magnitude of the FFT
pow_frames = ((1.0 / NFFT) * ((mag_frames) ** 2)) # Power Spectrum
6.滤波器组
计算滤波器组的最后一步是对功率谱在梅尔尺度上应用三角滤波器(通常为40个滤波器,Mel-scale nfilt=40)以提取频段数据。MEL-Scale的目标是模仿人耳对声音的非线性感知,在较低频率下具有更高的区分度,而在较高频率上较小的区分度。我们可以使用以下公式在赫兹(f)和MEL(m)之间进行转换: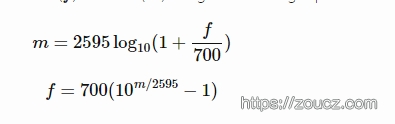
滤波器组中的每个滤波器都是一个三角形,在中心频率处的值为1,并向0线性减小,直到到达值为0,也是下一个相邻滤波器的中心频率,如下图所示: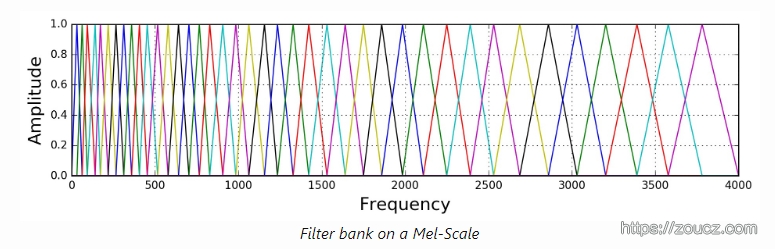
可以使用下面的公式和代码计算:
low_freq_mel = 0
high_freq_mel = (2595 * numpy.log10(1 + (sample_rate / 2) / 700)) # Convert Hz to Mel
mel_points = numpy.linspace(low_freq_mel, high_freq_mel, nfilt + 2) # Equally spaced in Mel scale
hz_points = (700 * (10**(mel_points / 2595) - 1)) # Convert Mel to Hz
bin = numpy.floor((NFFT + 1) * hz_points / sample_rate)
fbank = numpy.zeros((nfilt, int(numpy.floor(NFFT / 2 + 1))))
for m in range(1, nfilt + 1):
f_m_minus = int(bin[m - 1]) # left
f_m = int(bin[m]) # center
f_m_plus = int(bin[m + 1]) # right
for k in range(f_m_minus, f_m):
fbank[m - 1, k] = (k - bin[m - 1]) / (bin[m] - bin[m - 1])
for k in range(f_m, f_m_plus):
fbank[m - 1, k] = (bin[m + 1] - k) / (bin[m + 1] - bin[m])
filter_banks = numpy.dot(pow_frames, fbank.T)
filter_banks = numpy.where(filter_banks == 0, numpy.finfo(float).eps, filter_banks) # Numerical Stability
filter_banks = 20 * numpy.log10(filter_banks) # dB
经过上面的操作,将滤波器组应用于信号的功率谱,就得到了下面的谱图: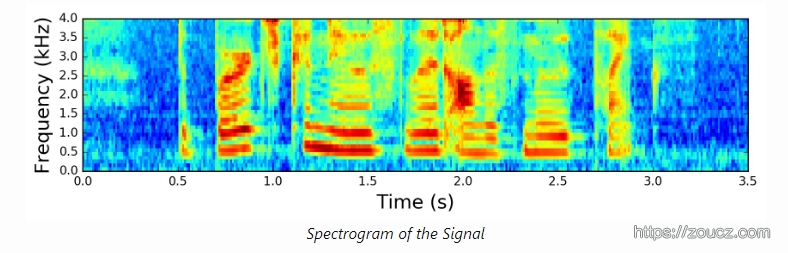
如果MEL-SCALE的滤波器组就是所需的特征,就可以跳到均值标准化的步骤了。
7.梅尔倒谱系数(MFCCs)
在前一步骤中计算的滤波器组系数是高度相关的,这在一些机器学习算法中可能是有问题的。因此,我们可以应用离散余弦变换(DCT)对滤波器组系数进行去相关,从而得到滤波器组的压缩表示。通常,对于自动语音识别(ASR),得到的倒谱系数2-13被保留,其余的被丢弃。丢弃其他系数的原因是它们代表了滤波器组系数的快速变化,而这些细微的细节不利于自动语音识别(ASR)。
mfcc = dct(filter_banks, type=2, axis=1, norm='ortho')[:, 1 : (num_ceps + 1)] # Keep 2-13
将正弦提升应用于MFCC,以降低对较高MFCC的强调,这种方法被认为可以改善在有噪声信号中的语音识别。
(nframes, ncoeff) = mfcc.shape
n = numpy.arange(ncoeff)
lift = 1 + (cep_lifter / 2) * numpy.sin(numpy.pi * n / cep_lifter)
mfcc *= lift #*
MFCCs的结果: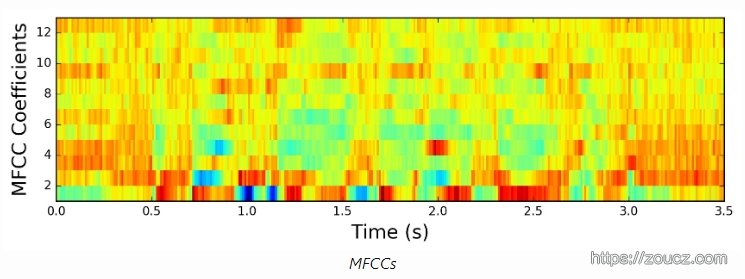
8.均值标准化
前面提到的,为了平衡频谱和改善信噪比(SNR),我们只需从所有帧中减去每个系数的平均值即可。
filter_banks -= (numpy.mean(filter_banks, axis=0) + 1e-8)
均值标准化后的滤波器组: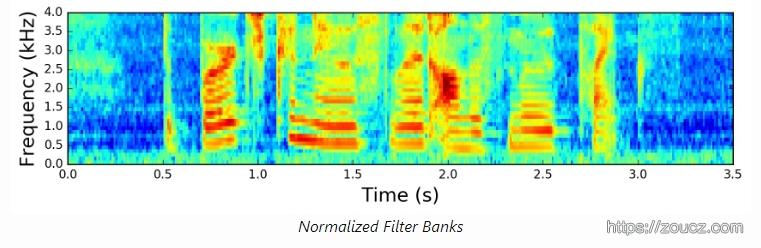
MFCCS也做类似的处理:
mfcc -= (numpy.mean(mfcc, axis=0) + 1e-8)
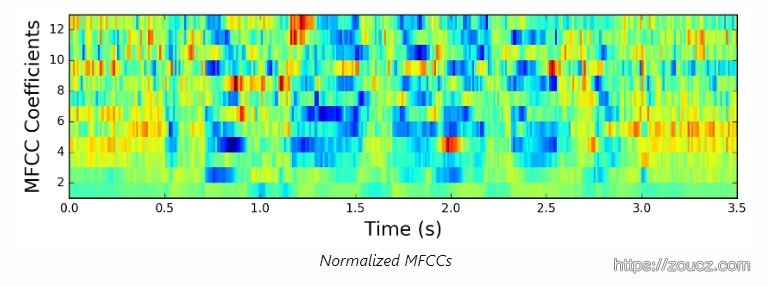
9.滤波器组与MFCCs的对比
至此,我们从动机和实现两个方面讨论了计算过滤器组和mfcc的步骤。值得注意的是,计算滤波器组所需的所有步骤都是由语音信号的性质和人类对这些信号的感知所驱动的,相反,计算MFCC所需的额外步骤是受一些机器学习算法的限制所驱动的。为了去除滤波器组系数的相关性,需要离散余弦变换(Dct),这一过程也被称为白化。当高斯混合模型-隐马尔可夫模型(GMms-hmms)开始流行的时候,MFCC和GMms-hmms共同发展成为了自动语音识别(ASR)的标准方法。随着语音系统中深度学习的出现,人们可能会质疑MFCC是否仍然是正确的选择,因为深度神经网络对高度相关的输入不太敏感,因此离散余弦变换(DCT)不再是必要的步骤,离散余弦变换(DCT)是线性变换,为它丢弃了高度非线性的语音信号中的一些信息,因此是不合适的。
质疑傅立叶变换是否是必要的运算也是一个合理的疑问。考虑到傅立叶变换本身也是一种线性运算,忽略它并尝试直接从时域中的信号中学习可能是有益的。事实上,最近的一些工作已经尝试了这一点,并得到了不错的结果。然而傅里叶变换操作是一个很难学习的操作,且可能会增加获得相同性能所需的数据量和模型复杂性。但同时,在进行短时傅立叶变换(STFT)时,我们假设信号在这么短的时间内是平稳的,因此也不会引起严重的问题。
如果机器学习算法对高度相关的输入不敏感,则使用MEL-SCALE的滤波器组。如果机器学习算法易受相关输入的影响,则使用MFCC特征。
本文链接:https://www.zoucz.com/blog/2019/05/07/9e6fb5f0-7095-11e9-90b5-eb40e9720ed0/
