nodejs drain事件与自定义流
很早之前看到过写drain的文章,最近我在工作中也遇到了个需要自己控制流的场景,整理了一下相关资料,在这里记录一下吧。
这个是之前看的关于drain事件的文章 探究 Node.js 中的 drain 事件
然后是一些讲Stream讲的不错的文章:
我的场景
业务场景如下:
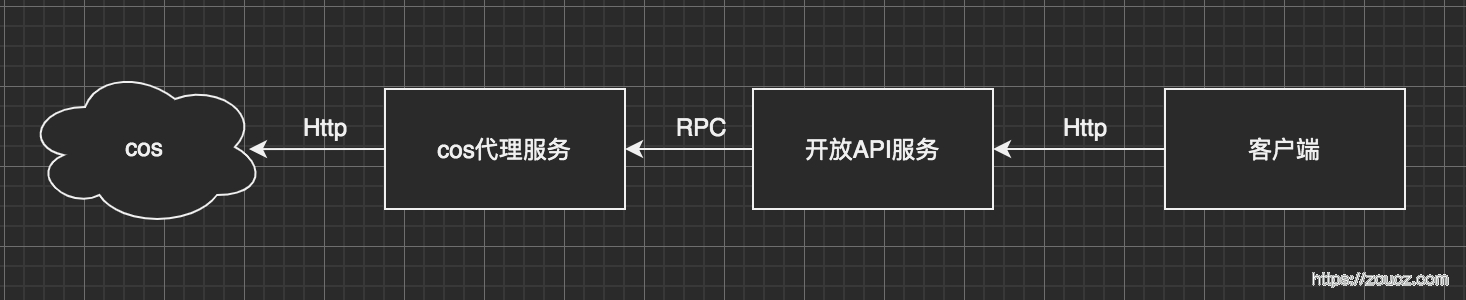
因为开放API服务和真正的cos之间隔了一层rpc的代理,这里在下载大文件时有两点问题:
- 单次rpc请求包体不宜过大
- cos代理服务和开放API服务的内存都有限,不能把大文件整个读入内存,需要做分块控制
那么最自然的思路是,把大文件的分片rpc调用读取,基于nodejs的Stream封装成一个可读流,这样就不需要自己做流程控制了。
伪代码:
import {Readable, ReadableOptions} from "stream"
class RpcReadStream extends Readable{
public constructor(options?: ReadableOptions){
super(options)
}
public async _read() {
let buf = await this._readFromRpc()
this.push(buf)
}
private _end(){
this.push(null)
}
private async _readFromRpc():Promise<Buffer>{
//TODO
return Buffer.from("todo")
}
}
let rpcReadStream = new RpcReadStream()
rpcReadStream.pipe(ctx.response)
做的时候顺便做了一些测试,记一些很弱智但是容易搞错的点,另外还有和探究 Node.js 中的 drain 事件文章中结论不一致的地方,也记录一下吧。
一些问题
记住调用pipe后就交出了stream的控制权
我很弱智的在调用 rpcReadStream.pipe(ctx.response) 后,还尝试在别的地方通过 rpcReadStream.pause() 来停止数据读入。 结果发现并没有作用, _read函数还是在不断调用,当时有点懵,还想了会儿。
后来在
writeStream.addListener("drain",()=>{})
里边加上一些log,果然drain在不断触发,而pipe的逻辑里边drain触发的时候是会将可读流resume的。。。
这里还是记录一下吧,一旦将可读流pipe出去后,就不要再尝试操作它了,控制权已经交出去了,除非执行unpipe。
若不限流,数据会在写缓冲区无限积压
探究 Node.js 中的 drain 事件文章中描述的,限流和不限流时内存表现差不多。
而我这边写了个生产快、消费慢的demo代码,在不限流时,数据会在写缓冲区无限积压,打印writeableLength不断增大。
反之,在加上用drain事件限流的逻辑后,readableLength 和 writeableLength 的长度,都相对稳定。
唯一不同的是我的demo是从内存中随机生成内容,而文章中用的是fs.createReadStream,或许其内部实现比较奇怪,在pause后还会读取,或者水位线开的特别高?后续有机会求证下~
可读流水位线的作用?
目前看到的文档和文章里边,大多是讲可写流的水位线满了之后,背压触发可写流停止读取数据,但是对于可读流的水位线作用并没有深入讨论。
可写流:
- 水位线满,writeStrea.write返回false,一般用来pause可读流
- 数据发送成功 ,缓冲区数据减少,水位线未满,触发 “drain” 事件,一般用来恢复可读流
- 产生场景是可读流在流动模式下,生产速度大于消费速度
可读流:
- 水位线满调用readStream.push返回false
- 恢复的标志是数据被读取?
- 产生的场景是在暂停模式下,因数据不消费导致积压满?
经验证,确实是这样。给readStream绑定”readable”事件后,让readStream进入暂停模式,然后在_read函数里打出push的返回值和readableLength,默认增加到16k后,push返回fasle,不再读取数据。
而一旦调用readStream.read()读取缓冲区中的全部数据,水位线即恢复到不满状态,重新开始读取数据。
可以理解为,可读流的水位线,一般在读流的暂停模式下起作用;而可写流的水位线,一般用来控制流动模式下可读流的状态。
本文链接:https://www.zoucz.com/blog/2020/07/31/544e82e0-d28b-11ea-90b5-eb40e9720ed0/
